Making Flow more accessible
Our dedicated services are developed to fulfill the whole product cycle. They range from discovery, branding, design over to development and continuous improvements in order to achieve the best outcome.
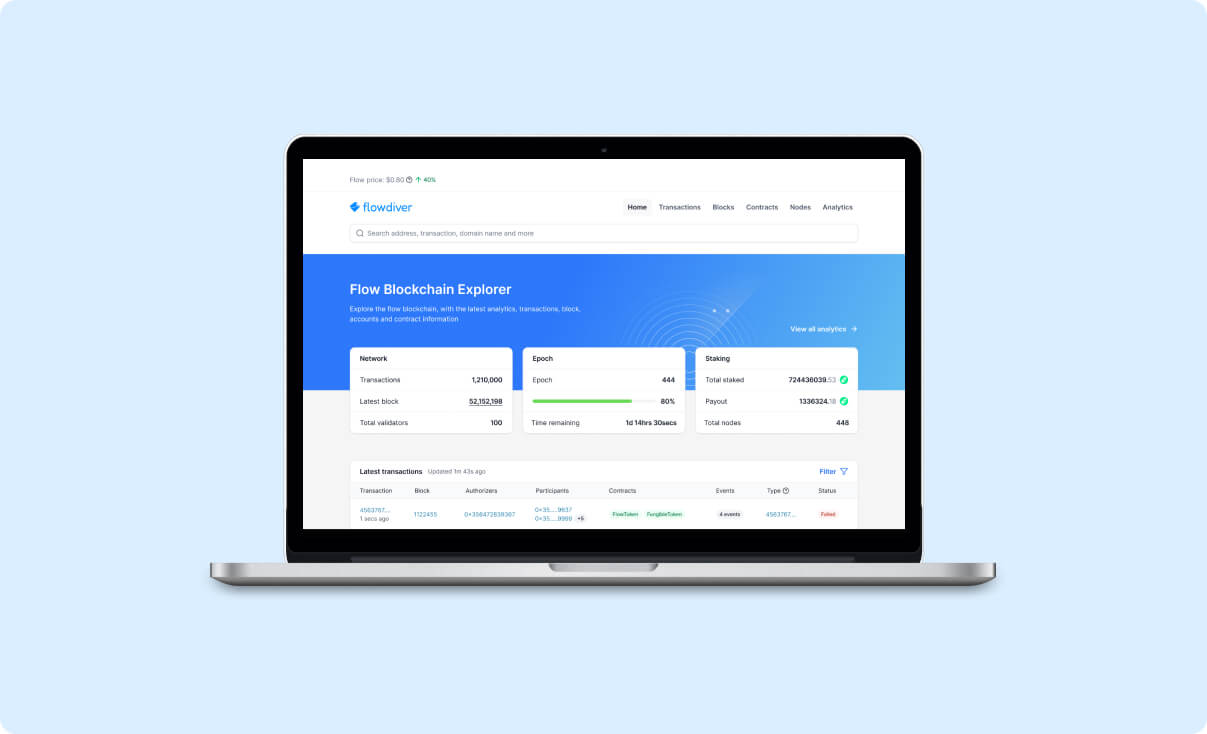
Introduction
Background
Indexing a blockchain to transform it into a usable dataset is pivotal in enhancing the developer experience for applications integrating with or utilising blockchain data. Recognising the importance of readily accessible and well-structured data for developers, we identified a need to augment the data offerings for Flow. Our primary initiative? Constructing an exhaustive index of all transactions and events and making them accessible through a block explorer.
Block explorers are indispensable to a blockchain's infrastructure. They offer a window into the blockchain, allowing users to track and understand all on-chain activities. Our assessment of the current block explorers on Flow revealed a gap; they didn't align with our requirements. This spurred our mission to create a tool not just for ourselves but for the entire Flow community.
Objective
Our goal is twofold: to comprehensively index all events and transactions on Flow and to launch a public block explorer tailored to the needs of developers and users on the Flow blockchain. Ambitiously, we aimed to create the minimum viable product (MVP) within a tight 8-week timeframe.
Challenges Faced
Data Scraping
Assembling and structuring the chain history for Flowdiver posed significant hurdles, consuming more time than anticipated. Specific issues included:
- Slow past sporks: The access nodes were sluggish and subject to rate limitations, making the use of these nodes a prolonged endeavour.
- Badger files: LFTP emerged as the go-to solution for downloading sizeable spork files, thanks to its parallel downloading capability.
- Storage strategy: Our initial approach of saving each transaction body with its unique hash for deduplication proved inefficient.
- Data duplication: Some sporks presented replicated transaction data in the badger file, necessitating a dual-pass import to distinguish between successful and unsuccessful transactions.
- Duplicated transactions: In some of the sporks transactions where wrongly duplicated in the badger file. There was a pattern to this so we figured out how to do a double-pass over transactions first adding everything successful and then iterating over failed transactions only adding the ones that where not already there.
- Forks: a protocol dump might include forks so be aware of using primitive badger operations to ingest data as you might ingest invalid data.
ServiceEvents Documentation
- Misconceptions regarding the onset of ServiceEvents; they were initially believed to start from spork18 but could have commenced as early as spork15.
- Hiccups in associating service events with a distinct transaction ID for each block.
- Inconsistencies in epoch durations and rewards dissemination.
Fee structures on Flow
The fee structures underwent multiple transitions, ranging from non-existent to standard, and finally to dynamic fees incorporating gas and execution effort.
Solutions Developed
- Initiated with the Flow-EventDumper tool sourced from GitHub.
- Innovated the blockexplorer-spork-indexer, inspired by the original tool
- closed source
- Workflow involved:
- Spork archive downloads.
- File unpacking.
- Specialised spork indexer code execution to convert badger files into a JSON structure.
- Deploying the Blockexplorer backend to convert JSON files into concrete database entries.
Infrastructure
Selecting the appropriate infrastructure to construct a vast transactions database that was both lightning-fast and budget-friendly proved challenging. Cloud-based solutions were immediately dismissed due to steep operational costs and potential future ingress/egress charges. We opted for a high-performance dedicated server, complemented by smaller servers for real-time indexing, backup, and redundancy.
Database
Our journey began with Supabase for our Postgres database. However, we soon confronted its limitations, leading us to transition to Hasura with a GraphQL API—a solution that resonated with our requirements in terms of speed, flexibility, and power.
User Experience
The challenge lay in juxtaposing intricate blockchain data with a user-centric interface. Our strategy involved scrutinising other block explorers to discern their UX methodologies, ultimately crafting our unique design informed by this analysis and our firsthand experience.
Our Approach
Research & Planning
We spent several months discussing the need for a new block explorer on Flow. Upon deciding to build one, we focused on delineating the ideal features for both the MVP (Minimum Viable Product) and the fully featured version, and identifying potential users.
We engaged developers from various projects, inquiring about specific features they desired in a block explorer and what they appreciated in other ecosystems.
In our investigation of over 18 block explorers, we documented aspects that caught our attention both positively and negatively.
Leveraging this comprehensive research and our own vast experience with block explorers, we crafted the specifications and design for our MVP.
Choosing the Tech Stack
- Front end - Github, Storybook, Figma, FeatureOS.
- Back end - Hasura, Postgres, GraphQL, Kubernetes, Flux (gitops).
Design & User Experience
Our design ethos stood on four foundational pillars: Usability, Clarity, Reliability, and Engagement. These weren't buzzwords; they signified our commitment to crafting an intuitive, precise, and captivating user journey.
Beginning with the discovery phase, we prioritised understanding user needs and competitor insights, which steered our path from preliminary wireframes to a polished UI. We consistently aimed for a blend of familiar and innovative UI patterns.
Our design journey was characterised by ongoing iteration. Using feedback from users and beta tests, we adapted our design to cater to genuine user requirements—a principle we plan to retain throughout the platform's existence.
Design, for us at Find Labs, transcended being just a phase. With tools like Figma and Storybook, our workflow was seamless, while FigJam enhanced our collaborative efforts.
Development & Iteration
- Back end: We were driven by a fundamental principle: simplicity is paramount. Positioning ourselves higher on the service abstraction hierarchy is usually more beneficial, but this comes at a cost. Striking the right balance was essential.
- Front end: Our development approach was iterative, encompassing discovery, design, testing, and handover phases. Adhering to Atomic Design principles, we built a component library for the site. This agile methodology permitted designers and developers to revisit phases for modifications or to initiate new tickets for feature enhancements. Design groundwork was laid in Figma, and subsequent development was achieved using Storybook.
Testing
Our testing began with a comprehensive feature test list, examining each page meticulously. Bugs identified were cataloged on Linear. After internal evaluations, we invited select individuals for preliminary testing, even before our data set was finalised. A month-long public Beta testing followed, during which we rolled out supporting services like our roadmap. We sought feedback from the Flow community, incorporating many of their suggestions before the official MVP launch. After finalising our data set and making the necessary adjustments, we unveiled our roadmap on FeatureOS, granting the public access to our future plans, and allowing them to request features, vote, and report bugs.
Features & Functionalities
- Search Functionality: Users can search for specific blocks, transactions, addresses and names.
- Real-time data: The latest transactions and blocks as they come through the network along with the full history of the blockchain. Analytics: Providing insights into transaction volumes, active accounts, contracts added and other useful stats about the blockchain, transactions and nodes.
- Responsive Design: Ensuring optimal viewing and interaction experience across a wide range of devices.
Results & Feedback
- Performance Metrics: Share stats like page load times, server uptime, and other relevant KPIs that showcase the success of the block explorer.
- 91 Countries
- Engangement rate of 62.56%
- User Feedback: Include testimonials or feedback from users about the ease of use, clarity, and overall experience.
- Recognition: After the launch of Flowdiver it quickly became the industry default block explorer across the whole Flow ecosystem.
Key Learnings
- The disk used for storing badger files really matters. The faster the better here, but especially the bump to NvME compared to HDD gives a huge boost in performance.
- Beware of using *a lot* of small files, as some FS on linux will report that you are out of space even if you have plenty of disk/inodes left. We stored each transaction_body in its own file and that was too much. We ended up in newer iterations with just duplicating the body into transactions that resulted in larger files but no errors of out of space that was hard to debug.
- There are a lot of corner cases in the protocol db badger files that are very important to understand in order to ingesting wrong data. For instance just looping over all events in a dump *can* yield in invalid event since the dump might have forks. Some sporks have duplicated transactions also.
Conclusion & Future Plans
Reflection
The journey to build Flowdiver, especially within such a tight timeframe, underscored the importance of meticulous organisation and relentless efficiency. It's a testament to our prowess that we were able to conceive, design, and deploy such a remarkable tool for the Flow ecosystem in a limited period.
This endeavour wasn't merely about creating a product; it was an invaluable learning curve for the Find Labs team. Crafting Flowdiver gave us a deep dive into multitasking across different layers of the tech stack and resolving intricate challenges inherent in retrieving and processing historical Flow data.
Our amassed experience and the insights garnered from this project position us as a frontrunner in the space. We stand ready and equipped to address an expansive range of challenges for those keen on tapping into the full potential of the Flow blockchain seamlessly.
Upcoming Enhancements
Our commitment to Flowdiver doesn't end with its inception. We're dedicated to its continuous refinement, enhancing features and elevating user experiences. On the horizon, we have plans to introduce:
- Human-readable transfers, encompassing both fungible and non-fungible tokens.
- Contract name-based search functionalities.
- Liquidity pool and DEFI support
- NFT details
- Richer node details
- Delegation tools for staking Flow to specific nodes.
- More comprehensive analytics to equip users with deeper insights.
Find Labs API
In our ongoing efforts to empower the developer community, we're excited to announce that we will soon be launching an API. This will grant developers building on Flow access to our high-quality data, fuelling their projects with the best possible information.
Driven by passion and innovation, we remain steadfast in our commitment to pioneer top-tier solutions, continuously affirming our reputation as leaders in blockchain technology.
Want to find out more?
© 2025. Find BC International LLC. All rights reserved